

If your tracking lives in the browser, you do not control it. Browsers block pixels, iOS drops signals, and ad blockers kill scripts before they even load.
Then, your team sits in a meeting staring at three different revenue numbers, wondering which one is a lie. This is why most Meta dashboards look like works of fiction. You need to move the logic. This is not about a quick fix or a new plugin.
You need a Server-Side Tagging Architecture to take back control of your data layer and stop the revenue leak caused by browser-based limitations.
What is Server-Side Tagging?
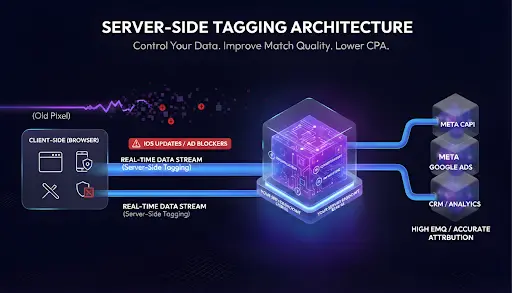
Server-Side Tagging Architecture moves tracking off the browser and into infrastructure you own. Instead of sending conversion data straight from the user’s device to Meta or Google, events follow a cleaner path:
Browser → Your Server Endpoint → Ad Platforms
Usually, this happens through a server-side Google Tag Manager (GTM) container. This is not magic. It is engineering done right. With a server in the middle, you decide what gets sent, when it gets sent, and where it goes.
Not Safari. Not iOS. Not an ad blocker. You are creating a private post office for your data. You sort the mail, verify the addresses, and then send it out. This is a critical step in fixing the “Franken-Stack” problem where tools don’t talk to each other.
Why Browser Tracking is Failing Your Agency
Standard pixels lose data constantly. When a script is blocked or a cookie is dropped, the sale still happens, but your tracking misses it. This creates a massive gap between reality and your reports.
When Shopify shows one revenue number and Meta shows another, you are optimizing based on hallucinations. You cannot scale an account if you do not know which ads actually drove the cash. A Server-Side Tagging Architecture captures the conversion at the server layer. If the transaction exists in the backend, it gets recorded.
Common Data Failures and Their Fixes
| What You See | What Is Actually Broken | The Structural Fix |
|---|---|---|
| Meta reports more sales than Shopify | Duplicate firing without deduplication | Enforce event IDs at the server layer |
| Shopify revenue is higher than Meta | Browser pixel blocked or delayed | Send purchase events via server-side CAPI |
| Event Match Quality (EMQ) below 6.0 | Missing or inconsistent identifiers | Pass hashed PII from the server |
| Conversions show up late in Ads Manager | Scripts firing after consent delays | Trigger events from a server endpoint |
| Retargeting audiences shrinking | Lost signals from ad blockers and iOS | Recover signals with first-party data |
| ROAS looks great, cash does not match | Inflated or missing conversions | Validate events against backend truth |
Architecture Beats Plugins Every Time
Most agencies try to solve this with a one-click plugin. Here is the problem: plugins break. Themes update and overwrite your code. Edge cases get missed.
Basic tracking just forwards events like a relay race. A professional Server-Side Tagging Architecture adds governance. It is the difference between it works for now and a system that scales. A real architecture allows you to:
- Standardize events across every platform.
- Deduplicate pixel and server signals so you do not double-count.
- Mask sensitive data before it ever leaves your server.
- Route data differently based on the destination.
- Clean up the mess before it hits the ad manager.
If you are struggling to prove value because the numbers are messy, you might be dealing with the black box problem of broken GA4 setups. Building a custom server-side layer is the only way to get out of that box.
Solving the Cookie Loss Crisis
The future of tracking is not found in the browser. With Chrome following Safari and Firefox in phasing out third-party cookies by mid-2026, relying on client-side scripts is a losing strategy. Cookie loss is not just a technical hurdle. It is a fundamental shift in how we identify users.
Server-Side Tagging Architecture allows you to set first-party cookies from your own domain. Since the data is coming from your server (e.g., track.yourdomain.com), it is not treated as a third-party intrusion. This extends your window for attribution and ensures your compliance with evolving privacy laws like GDPR and CCPA. You decide exactly what data is stripped or hashed before it ever reaches a third-party vendor.
Your Frontend Gets a Break
Too many scripts make websites slow. Slow sites kill conversion rates. When you move tracking logic off the frontend, you reduce tracking bloat. This is especially true on mobile devices where processing power is limited.
By sending one stream of data to your server instead of firing ten different scripts in the browser, the page loads faster. Faster pages do more than help your SEO. They keep people on the site long enough to actually buy something.
D’t Let Old Vendors Break Your N
How to Tell if Your Setup is Actually Working
A real implementation is verifiable. You should not have to guess if your data is accurate. In a proper Server-Side Tagging Architecture environment, you should see:
- “Server” listed as a data source in Meta Events Manager.
- Event Match Quality (EMQ) above 8.0.
- Proper deduplication between browser and server events.
If you cannot confirm these three things, you do not have a tracking system. You have a guess. This lack of precision is exactly why creative agencies bleed margin on technical scope creep. They spend hours chasing missing data instead of billing for strategy
Stop the Retargeting Bleed
When tracking fails silently, your retargeting audiences shrink. You end up overpaying for top-of-funnel traffic because you cannot see the users when they return.
Most brands see their retargeting pools grow within weeks of switching to a Server-Side Tagging Architecture. It is not because traffic increased. It is because they stopped losing users to browser restrictions. This is a foundational part of building a “data-first” culture in your agency.
The Reality of Clean Data
Clean architecture lasts. By implementing a professional tracking layer, you are not just fixing a pixel. You are building a system your entire marketing stack can trust.
You get:
- Stable deduplication that prevents over-reporting.
- Consistent event definitions across all channels.
- Higher match quality for better ad delivery.
- Long-term control over your data privacy and compliance.
This is not a nice to have anymore. If you want to scale your agency without hiring an army of data engineers, you need systems that handle the heavy lifting for you. In a world of cookie loss, the agencies that own their data infrastructure will be the ones that survive the future of tracking.
Is your tracking actually telling the truth?