

Have you ever felt like you’re speaking a different language when trying to get AI to follow your instructions? You’re not alone. Prompt engineering—the craft of instructing large language models (LLMs)—is both an art and a science. And training LLMs for specific tasks requires more than just feeding it data.
Imagine you’re a conductor leading an orchestra of artificial intelligence. Sometimes, everything aligns, and the AI delivers flawless, deterministic outputs. Other times, it surprises you with unexpected, non-deterministic results. This unpredictability is part of what makes working with LLM large language models both exciting and challenging.
In this blog post, we’ll unpack the mechanics behind deterministic vs. non-deterministic behavior in LLMs, explore techniques for autonomous prompt engineering in large language models, and provide strategies to help you guide outputs more effectively.
Deterministic Behavior in Large Language Models (LLMs)
Understanding deterministic behavior is foundational if you want to master how to train LLM for specific tasks. Deterministic outputs mean the model gives the same response to the same prompt every time—crucial for many real-world applications.
Key characterstics include:
1. Consistency – Identical prompts yield identical outputs under the same conditions.
2. Precision – Outputs follow a strict format with minimal deviation.
3. Promt and context-dependency – Minor changes to prompt wording can still shift results.
4. Temperature-sensitive – This affects the randomness of outputs. Lower temperatures (~0) favor deterministic behavior, while higher temperatures introduce more variability.
5. Seed-dependent – Setting a fixed random seed locks the model’s behavior.
6. Low creativity – Output tends to be accurate, but less innovative.
7. Prompt-sensitive – Prompt phrasing strongly shapes output results.
To illustrate these characteristics, let’s look at a comparison between deterministic and non-deterministic outputs:
| Aspect | Deterministic Output | Non-Deterministic Output |
|---|---|---|
| Consistency | Same output for same input | May vary for same input |
| Creativity | Limited, more predictable | Higher, more diverse |
| Precision | Exact wording and formatting | May have slight variations |
| Temperature | Low (close to 0) | Higher (0.5 – 1.0) |
| Reproducibility | Highly reproducible | Less reproducible |
| Use Cases | Data analysis, fact-checking | Creative writing, brainstorming |
These properties help developers build controlled, reliable applications using LLM large language models.
Why Deterministic Responses Matter in LLM Applications
When implementing autonomous prompt engineering in large language models, deterministic behavior offers numerous advantages:
1. Reliability in critical applications:
When you’re dealing with applications that require high accuracy and consistency, such as medical diagnosis assistance or legal document analysis, predictable responses are crucial. You can rely on the LLM to provide the same output for a given input, reducing the risk of errors or inconsistencies.
2. Easier debugging and testing:
With deterministic behavior, you can more easily identify and fix issues in your prompt engineering or application logic. When you know exactly what output to expect for a given input, it’s simpler to spot discrepancies and troubleshoot problems.
3. Reproducibility in research and development:
In scientific research or when developing AI-based solutions, reproducibility is key. Deterministic outputs allow you and your colleagues to replicate results across different environments or time periods, ensuring the validity of your findings.
4. Consistent user experience:
For customer-facing applications, predictable responses help maintain a consistent user experience. Users can rely on getting the same information or assistance for similar queries, building trust in your system.
5. Improved version control:
When working on iterative improvements to your LLM-based applications, deterministic behavior makes it easier to compare outputs across different versions. You can clearly see how changes in your prompts or model affect the results.
6. Enhanced security and safety:
In scenarios where security is paramount, such as in financial transactions or sensitive data handling, predictable responses reduce the risk of unexpected behavior that could lead to vulnerabilities.
7. Easier integration with other systems:
When you’re integrating LLM outputs with other software systems, deterministic behavior simplifies the process. You can design your integrations around expected outputs, reducing the need for complex error handling or edge case management.
8. Compliance with regulations:
In industries with strict regulatory requirements, such as healthcare or finance, deterministic outputs can help ensure compliance by providing consistent, auditable results.
9. Efficient resource utilization:
Predictable responses often require fewer computational resources. Since the model doesn’t need to explore multiple possibilities, it can generate outputs more quickly and efficiently.
10. Simplified prompt engineering:
When you’re working with deterministic outputs, it’s often easier to refine your prompts. You can make incremental changes and observe their effects more clearly, leading to more effective prompt engineering.
To help you visualize these advantages, consider the following scenarios:
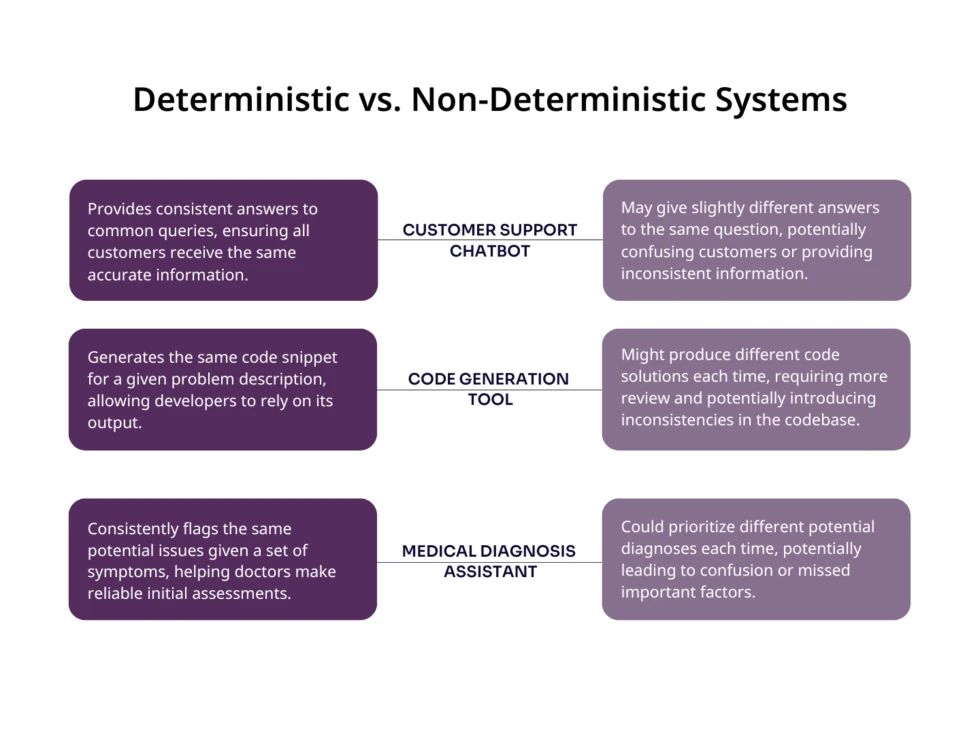
By leveraging these advantages, you can create more robust, reliable, and efficient applications using LLMs. However, it’s important to also be aware of the limitations and potential drawbacks of deterministic behavior, which we’ll explore in the next section.
The Drawbacks of Deterministic LLM Behavior
Despite its strengths, deterministic behavior isn’t always ideal when you’re learning how to train LLM for specific tasks. Be mindful of these limitations:
– Limited creativity and diversity: One of the most significant drawbacks of deterministic behavior is the lack of creativity and diversity in outputs. When you’re looking for innovative ideas or unique perspectives, deterministic responses may fall short. The model will consistently provide the same or very similar answers, potentially missing out on valuable alternative viewpoints
– Overfitting to specific prompts: Deterministic LLMs can become too reliant on specific prompt structures. If you always use the same prompts, the model may struggle to generalize or adapt to slightly different input formats, limiting its flexibility.
– Potential for amplifying biases: If a deterministic model has inherent biases in its training data or initial prompt engineering, these biases will be consistently reproduced in the outputs. This can lead to the reinforcement and amplification of problematic patterns or stereotypes.
– Lack of adaptability to context changes: In real-world applications, context often changes. Deterministic models may struggle to adapt to these changes, providing outdated or irrelevant information if the underlying data or circumstances have shifted since their training.
– Reduced ability to handle ambiguity: Many real-world scenarios involve ambiguous or open-ended questions. Deterministic models may struggle with these situations, often defaulting to a single interpretation rather than exploring multiple possibilities.
– Potential for predictable vulnerabilities: In security-sensitive applications, the predictability of deterministic outputs could be exploited by malicious actors who can reverse-engineer the model’s behavior.
– Limited learning from interactions: Unlike models that incorporate some level of randomness, purely deterministic models don’t “learn” or adapt from interactions. This can limit their ability to improve over time based on user feedback or new information.
– Risk of overconfidence in outputs: Users may place too much trust in the consistency of deterministic outputs, potentially overlooking the need for human verification or critical thinking.
– Challenges in simulating human-like interactions: In applications like chatbots or virtual assistants, purely deterministic responses can feel robotic or unnatural, potentially reducing user engagement.
– Difficulty in handling edge cases: Deterministic models may struggle with unusual or edge case scenarios that weren’t explicitly covered in their training data or prompt engineering.
To illustrate these limitations, consider the following comparison table:
| Scenario | Deterministic Model | Non-Deterministic Model |
|---|---|---|
| Creative Writing | Generates the same story plot each time | Produces varied and unique story ideas |
| Problem Solving | Always suggests the same solution | Offers multiple approaches to solve the problem |
| Conversation | Replies with identical responses to similar queries | Provides varied responses, making conversation feel more natural |
| Handling Ambiguity | Interprets ambiguous input in a fixed way | Explores multiple interpretations of ambiguous input |
| Adapting to New Information | Struggles to incorporate new context without retraining | Can potentially adapt responses based on recent interactions |
To mitigate these limitations, you might consider:
- Using a combination of deterministic and non-deterministic approaches depending on the specific requirements of your application.
- Regularly updating and refining your prompts to incorporate new information and contexts.
- Implementing human oversight and verification processes, especially for critical applications.
- Utilizing ensemble methods that combine outputs from multiple models or approaches.
- Incorporating user feedback mechanisms to help identify when deterministic outputs are falling short.
Strategies to Train LLMs for Consistent, Predictable Outputs
Let’s explore proven methods to promote determinism when engaging in autonomous prompt engineering in large language models:
Adjust Temperature Settings:
- Lower the temperature setting in your LLM to encourage more deterministic behavior. A temperature close to 0 will result in more predictable outputs.
- Experiment with different temperature values to find the right balance between determinism and creativity for your specific use case.
Use Precise, Standardized Prompts:
- Craft your prompts with extreme care and precision. The more specific and well-structured your prompt, the more consistent the output will be.
- Develop a standardized prompt template to train LLM for specific tasks with greater consistency.
Apply Seed Control:
- Many LLMs allow you to set a random seed. By using the same seed across different runs, you can ensure consistent outputs.
- Document and version-control your seeds along with your prompts for reproducibility.
Leverage Few-Shot Learning:
- Provide examples of desired inputs and outputs within your prompt. This technique, known as few-shot learning, can help guide the model towards more consistent behavior.
- Ensure your examples are diverse enough to cover various scenarios while maintaining the desired output structure.
Add Explicit Formatting Instructions:
- Include explicit instructions for output formatting within your prompt. This can help ensure consistent structure and presentation of the generated content.
- Consider using markdown or other lightweight markup languages in your instructions for more precise control.
Post-process Outputs:
- Develop post-processing scripts or functions to standardize the LLM’s output further. This can help correct minor inconsistencies and ensure a uniform final result.
- Be cautious not to over-process the output, as this might negate some of the LLM’s inherent capabilities.
Create a Controlled Vocabulary:
- Develop a list of preferred terms, phrases, or concepts for your specific domain or application.
- Incorporate this controlled vocabulary into your prompts to guide the LLM towards using consistent terminology.
Use Context Priming:
- Start your prompts with a clear, consistent context that sets the stage for the desired output. This can help anchor the model’s responses in a specific frame of reference.
- Update your context priming regularly to incorporate new information or changing circumstances.
Normalize User Inputs:
- Preprocess user inputs or queries to normalize format, spelling, and terminology. This can help ensure that similar intents result in consistent outputs, even if the initial inputs vary slightly.
- Be careful not to lose important nuances or context during normalization.
Utilize Prompt Chaining:
- Break complex tasks into smaller, more manageable subtasks using a series of prompts (prompt chaining).
- This approach can help maintain deterministic behavior for each subtask while allowing for more complex overall outputs.
Implement A/B testing:
- Maintain different versions of your prompts and regularly test them against each other to identify the most effective and consistent approaches.
- Use A/B testing to compare the performance of different prompt strategies in real-world scenarios.
Combine Outputs from Multiple Runs:
- Use ensemble methods to combine outputs from multiple runs or even different models.
- This can help average out inconsistencies while still maintaining a largely deterministic final output.
Here’s an example of how you might structure a prompt to encourage deterministic behavior:

This prompt uses clarity, role definition, formatting guidance, and tone setting—all critical elements when applying autonomous prompt engineering in large language models.
When learning how to train LLM for specific tasks, striking the right balance between deterministic behavior and creative flexibility is essential. Determinism can be a powerful ally for building structured, reliable, and auditable AI applications—especially in regulated or high-stakes environments.
However, it’s just one part of the broader LLM toolkit. By understanding both its advantages and limitations—and applying the right prompt engineering strategies—you can unlock the full potential of large language models LLMs for your application.